主题
计费方式
💡 快速说明
平台按 Token 计费。一次请求会把 普通输入 Token、缓存读取 Token、输出 Token 分开计算,再乘 当前分组倍率 得到最终费用。页面上的计算示例用于帮助你理解费用构成,最终以实际扣费和使用日志为准。
💰 Token 计费说明
先看模型基础价格
再看分组倍率和请求明细
如果你是第一次接触 Token 计费,先记住这句话:同一条请求里,普通输入、缓存读取、输出的价格通常不同;你所在的分组还会继续影响最终费用。
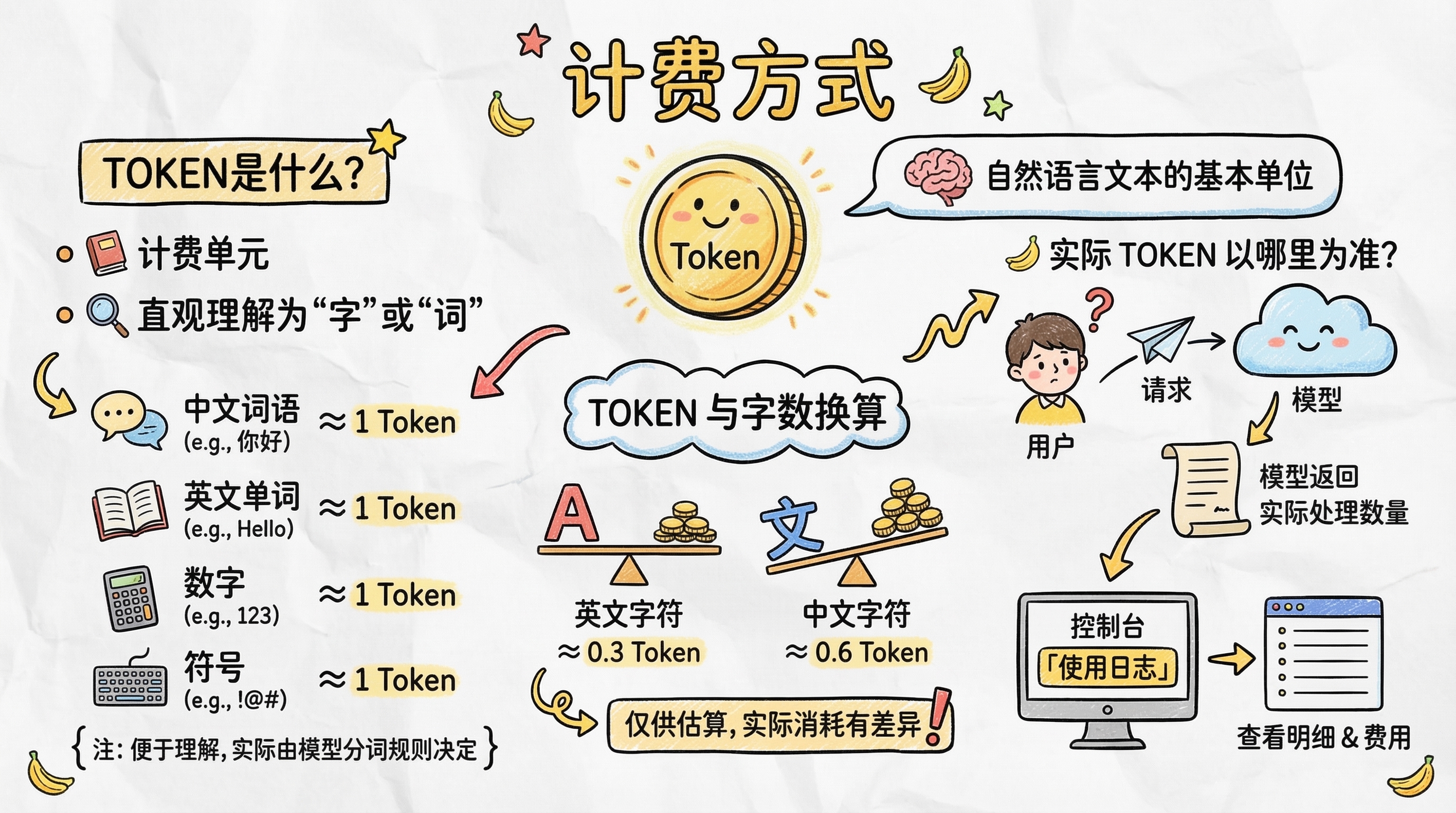
图 1:计费方式整体示意
✅ 先记住 4 件事
1️⃣ 平台按 Token 计费
Token 可以理解为模型处理文本时使用的计量单位。你发出的内容和模型返回的内容,都会换算成 Token 参与计费。
2️⃣ 不是所有 Token 都按同一个价格算
普通输入 Token、缓存读取 Token、输出 Token,通常会使用不同单价。命中缓存时,缓存读取部分往往更便宜。
3️⃣ 分组倍率会影响实际费用
模型展示的价格通常是基础价格。你所在的分组还会继续乘上对应倍率,得到你这边真正生效的价格。
4️⃣ 最终以实际扣费和使用日志为准
页面示例和手动估算主要是帮助你理解费用构成。真正结算时,请以系统实际扣费和使用日志中的记录为准。
如果你只想快速看懂
模型基础价格 → 当前分组倍率 → 本次请求里的普通输入 / 缓存读取 / 输出 Token → 得到最终费用
先记住这个顺序,后面看具体例子就会很容易。
🔤 Token 是什么
Token 是模型处理文本时使用的基础计量单位。它不是简单等于“一个字”或“一个单词”,但你可以先这样直观理解:
- 中文内容通常会占用一定数量的 Token
- 英文内容通常也会按单词、字符组合换算成 Token
- 数字、符号、空格等内容,同样也可能占用 Token
⚠️ 重要
1M = 1,000,000 Tokens,也就是 100 万 Tokens。不同模型的分词规则不完全一样,所以 Token 数只适合估算,实际仍以上游返回和使用日志为准。
Token 与字数的近似换算
一般可先按下面的粗略比例估算:
- 1 个英文字符 ≈ 0.3 个 Token
- 1 个中文字符 ≈ 0.6 个 Token
如果你只是想大概判断费用高低,这个估算已经够用;如果你要看精确扣费,请直接查看后面的使用日志说明。
🧮 一次请求是怎么计费的
一条请求的费用,通常由下面 3 部分组成:
普通输入 Token
也就是本次请求里按正常输入单价计费的那部分 Token。你可以把它理解成“未命中缓存的输入内容”。
缓存读取 Token
当请求命中缓存后,这部分 Token 会按缓存读取价格计算。通常这部分单价会低于普通输入价格。
输出 Token
也就是模型生成回答时消耗的 Token。很多模型的输出价格都会高于输入价格。
一次请求的常见计算方式可以写成:
text
总费用 =
(
普通输入 Token / 1M * 输入价格
+ 缓存读取 Token / 1M * 缓存读取价格
+ 输出 Token / 1M * 输出价格
)
* 当前分组倍率💡 提示
如果这次请求没有命中缓存,那么“缓存读取 Token”这一项就是 0,不会额外计费。
📊 分组倍率怎么影响实际价格
先看一个基础例子。假设 GPT-5.4 的基础价格是:
- 输入价格:
$0.500000 / 1M tokens - 输出价格:
$3.000000 / 1M tokens - 缓存读取价格:
$0.050000 / 1M tokens
这时,不同分组的实际价格就是“基础价格 × 分组倍率”。
下面以 GPT 相关分组 为例说明:
| 分组 | 倍率 | 输入价格 / 1M | 输出价格 / 1M | 缓存读取价格 / 1M |
|---|---|---|---|---|
default | 1.00x | $0.500000 | $3.000000 | $0.050000 |
V1 | 0.99x | $0.495000 | $2.970000 | $0.049500 |
V2 | 0.97x | $0.485000 | $2.910000 | $0.048500 |
V3 | 0.95x | $0.475000 | $2.850000 | $0.047500 |
V4 | 0.93x | $0.465000 | $2.790000 | $0.046500 |
V5 | 0.90x | $0.450000 | $2.700000 | $0.045000 |
GPT-Pro | 2.00x | $1.000000 | $6.000000 | $0.100000 |
⚠️ 注意
这一段是以 GPT 相关分组 为例做说明,因此不包含 Grok-Nx 这类面向其他模型资源的分组。GPT-Pro 分组会按 2x 计费,因此它的实际价格会高于默认分组。
🧾 GPT-5.4 计费示例
下面用一条真实计算逻辑更接近的例子说明:
1
先确认当前基础单价
以 GPT-5.4 为例,基础输入价格为 $0.500000 / 1M tokens,输出价格为 $3.000000 / 1M tokens,缓存读取价格为 $0.050000 / 1M tokens。
2
再看本次请求的 Token 明细
假设这次请求里,普通输入用了 1000 tokens,缓存读取用了 100000 tokens,输出用了 500 tokens。
3
最后乘上当前分组倍率
如果当前分组是 default,倍率就是 1x;如果是 V5,倍率就是 0.9x;如果是 GPT-Pro,倍率就是 2x。
以 default 分组为例,计算过程如下:
text
(
输入 1000 tokens / 1M tokens * $0.500000
+ 缓存 100000 tokens / 1M tokens * $0.050000
+ 输出 500 tokens / 1M tokens * $3.000000
) * 分组倍率 1
= $0.007000如果是同样一条请求:
- 在
V5分组下:$0.007000 × 0.9 = $0.006300 - 在
GPT-Pro分组下:$0.007000 × 2 = $0.014000
这样你就能直观看出:模型基础价格相同,但不同分组的最终费用会不同。
📍 实际扣费以哪里为准
每次请求的最终费用,请以控制台的 「使用日志」 为准。
你可以重点看这些信息:
- 本次使用的是哪个模型
- 普通输入 Token、缓存读取 Token、输出 Token 各是多少
- 本次请求实际扣了多少费用
- 如果有分组差异,最终生效的是哪个分组倍率
💡 提示
手动估算和最终扣费偶尔会有细微差异,这通常和模型分词、缓存命中、上游返回的实际 usage 有关。遇到这种情况,直接以使用日志为准即可。
❓ 常见问题
为什么同一句话,每次费用可能不一样?
因为模型不同、分组不同、是否命中缓存不同,都会影响最终费用。尤其是命中缓存时,缓存读取部分通常会按更低单价计算。
为什么输出价格通常比输入价格高?
很多模型本来就是这样定价的:生成内容比接收输入更贵。所以你看到“输出单价高于输入单价”是正常情况。
为什么我自己算出来,和日志有一点差异?
手动估算通常是为了帮助理解,不一定覆盖所有细节。实际扣费会根据上游返回的真实 usage 和系统最终结算结果确定。
缓存读取是不是一定会出现?
不一定。只有命中缓存时,才会出现缓存读取 Token;如果没有命中,这一项就是 0。